scRNA-seq数据分析实战(一)
single cell RNA-seq && SMART-seq2
上游分析:Linux
下游分析:用转录组思想初步了解探究单细胞转录组数据(注意:处理单细胞转录组和转录组是有很大区别的,完全将转录组思想应用于单细胞转录组数据分析是万万不可取的!!!)
scRNA-seq数据分析流程
以下分析流程以GSE111229数据为例(为什么用它呢,因为它数据量小呀,嘿嘿🤭)在进行分析之前,首先了解一下该套数据的基本情况。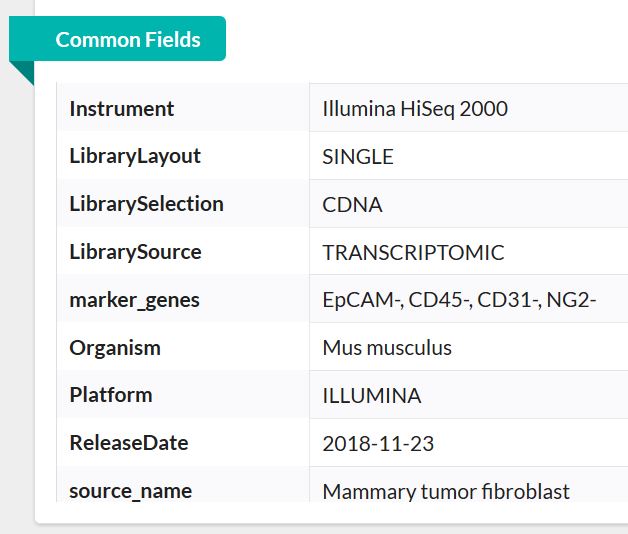
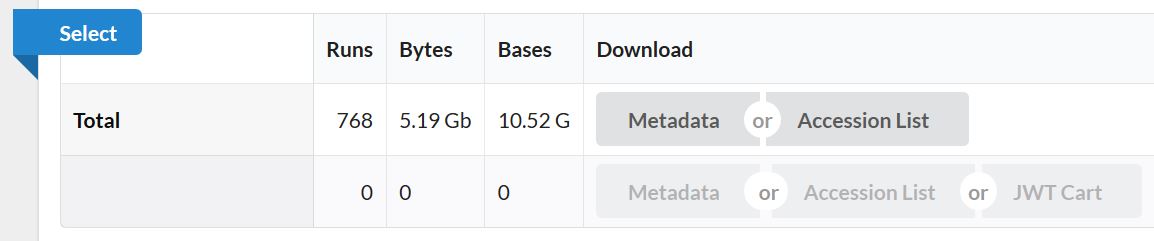
由此可基本了解,此数据为单端测序数据,物种为小鼠。768个样本即768个单细胞测序数据,总大小才10G。这在单细胞测序数据中真的是非常小!非常罕见啦!
😄数据分析上游(Linux)😄
因为是单细胞转录组测序数据,和转录组测序的上游分析没什么区别。所以以下分析流程都是在conda构建的rna环境下进行,这个环境也是很久之前搭建好的,在此不再赘述。
1 | conda activat rna |
运行上述代码后,可以看到提示符(prompt)左边多了一个(rna)环境,此环境里面,预先装好了处理RNA-seq数据所需要的相关软件。
数据下载
如果样本量不多,网速又不理想,推荐EBI-ENA数据库,此数据库下载网速还可以,另外该数据库除了提供SRA文件外,还提供FASTQ文件,省去了从NCBI下载SRA文件转为FASTQ文件的麻烦(如何单个文件数据量大,此格式转换步骤非常耗时)。
如果样本量特别多,网速又比较理想,推荐使用Aspera、prfetch、wget、curl。前两者大大优于后两者。Aspera Connect的下载速度是最快了,此方法也可以下载FASTQ和SRA文件,免去了SRA转至FASTQ的过程,该过程很耗时,十分耗时。
进入EBI官网,输入SRP号
1
2
3
以其中一个样本SRR6791132为例,点击SRR6791132进入下载界面,鼠标右键红色箭头处——“复制链接地址”
进入linux进行数据下载
1 | mkdir -p scRNA-seq/fastq && cd scRNA-seq/fastq |
注意注意,特别注意,要下载整套数据最好使用Aspera或者prefetch,本宝宝没有办法呀,网不好,空间也不大,linux中的数据操作只能用三个样本做演示了,熟悉一下分析流程。如果是整套数据,记得写小循环,放后台,就不用一直守着它了,最好是睡觉的时候跑,不耽误事。
质控
1 | #首先查看数据质量情况,进行如下操作 |
上述操作会得到html文件和zip文件
网页打开其中一个html文件可查看测序数据的质量,该数据整体质量还不错(质控报告解读教程)
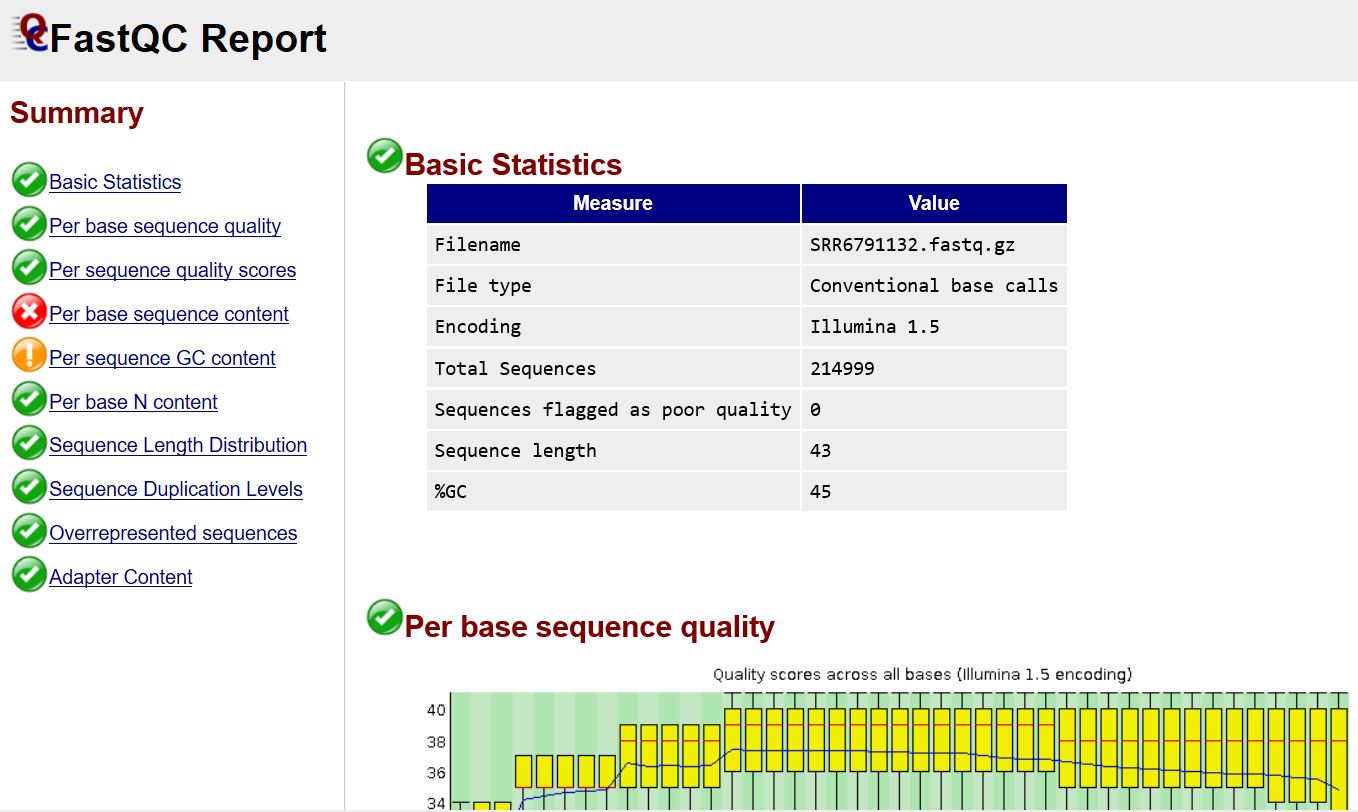
大部分测序数据都会出现如下情况,不过这个问题不大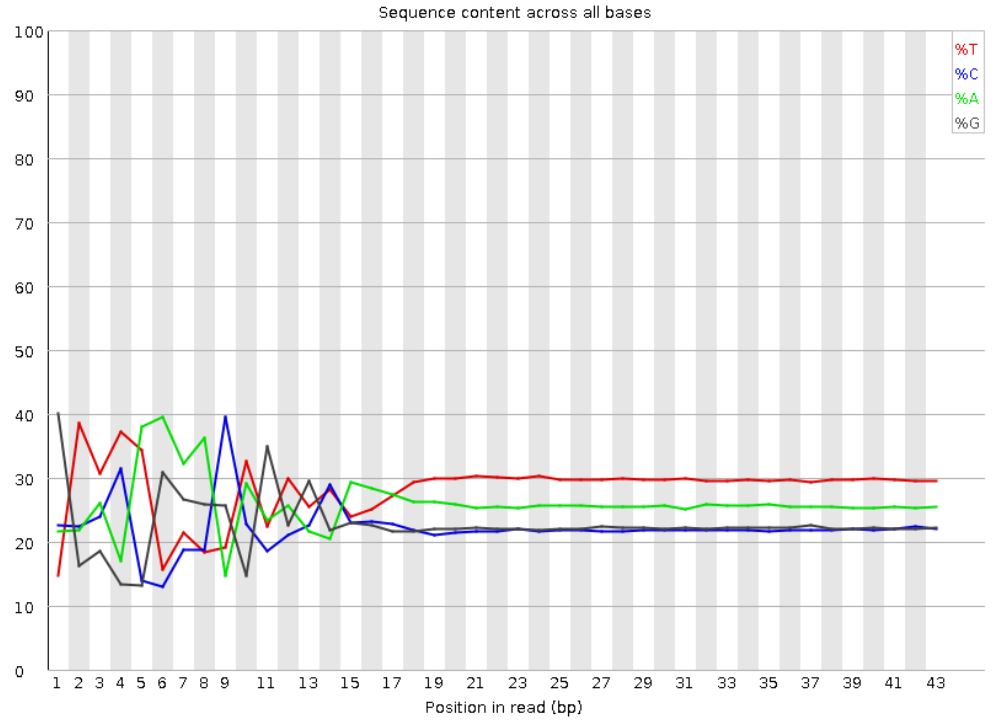
1 | #接下来过滤掉质量不好的数据,使trim_galore软件 |
比对
1、小鼠参考基因组
首先下载小鼠参考基因组,hisat2或者bowtie2构建小鼠参考基因组索引。也可以直接下载参考基因组索引文件。另外还需要下载小鼠参考基因组注释文件。(此步骤很早前处理RNA-seq数据时就已经完成了,就不再赘述)
hisat2构建的mm10参考基因组索引文件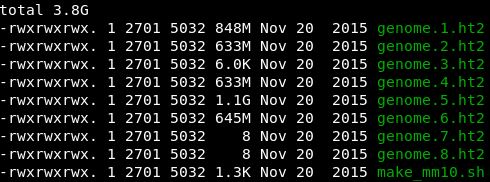
mm10注释文件
2、进行参考基因组比对
1 | #同参考基因组索引进行比对,生成bam文件。参考基因组索引一定是引用前缀"genome"。另外注意,此处数据为单端测序数据! |
比对结果如下:82.25%的比对率,比较的凑合了,一般情况最好90%以上,后两个数据的比对率实在不能看。真实处理环境一定要仔细调节过滤参数!!!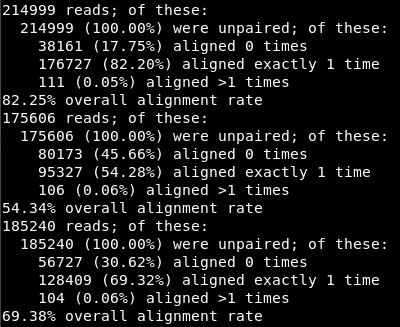
可以比较一下bam、fasatq、sam文件的大小。
sam文件远远大于bam和fastq文件。生信分析上游一定要对文件大小保持高度敏感,避免不必要的错误。另外,数据量大的话,可以在生成sam文件时通过|将结果进一步生成bam文件,这样可以大大节省存储空间。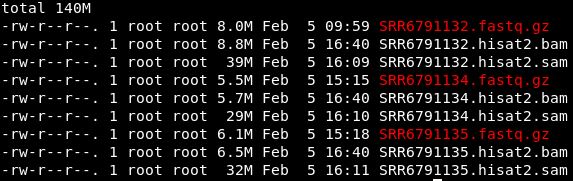
构建index文件
1 | ls *.bam | xargs -i samtools index {} |

生成reads表达矩阵
1 | gtf=/addfirst/reference/mouse/gencode.vM23.annotation.gtf |
 查看counts矩阵会发现绝大多数基因表达量都是0,因为对于大多数细胞来说,大多数基因都是测不到的,这个属于正常现象。在此,我们只用了3个样本做演示,总数据则有768个样本。
查看counts矩阵会发现绝大多数基因表达量都是0,因为对于大多数细胞来说,大多数基因都是测不到的,这个属于正常现象。在此,我们只用了3个样本做演示,总数据则有768个样本。
 理论上按照上面的分析流程生成的表达矩阵数据和下图中NCBI官网上的rawCounts.txt.gz的内容应该是差不多的,只是所用处理软件不同会有一点点区别。
理论上按照上面的分析流程生成的表达矩阵数据和下图中NCBI官网上的rawCounts.txt.gz的内容应该是差不多的,只是所用处理软件不同会有一点点区别。

至此,scRNA-seq上游分析结束,这里比较重要的是数据质量,数据质量直接决定比对的效率,影响最终生成的表达矩阵的可靠性。所以质控步骤要严格把控,送样测序也要选靠谱的公司。
😄数据分析下游(R)😄
数据(data.frame)的构建
如果是使用rawCounts数据进行下游分析,首先要对数据进行标准化,然后再做后续分析。该篇文章是使用rpkm的数据进行下游分析,这里也直接使用rpkm的数据进行下游分析。
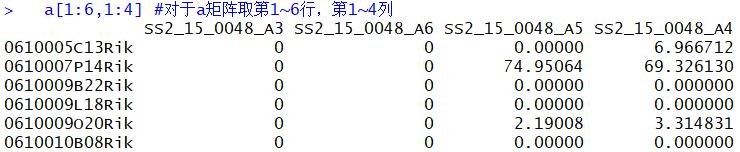
1 | a=read.table('../GSE111229_Mammary_Tumor_fibroblasts_768samples_rpkmNormalized.txt.gz',header = T ,sep = '\t') ##把表达矩阵文件载入R,header=T :保留文件头部信息,seq='\t'以tap为分隔符 |

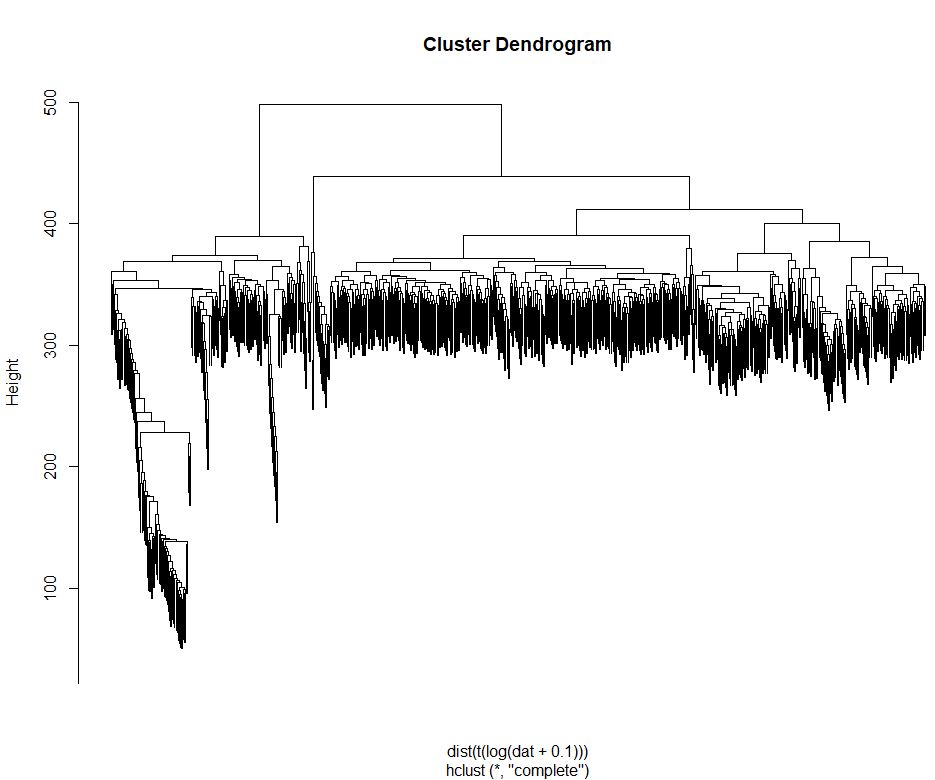
1 | #层次聚类 |

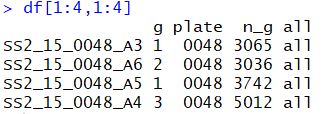
1 | #提取批次信息 |
检测是否存在批次效应
因为该篇文章使用两块384孔进行测序,所以要先确定两块板是否存在批次效应,如果存在,则两块板的样本不能合并分析,如果不存在批次效应,则两块板可以进行批次分析。
PCA主成份分析
1 | rm(list = ls()) ## 魔幻操作,一键清空~ |

tSNE分析
1 | rm(list = ls()) ## 魔幻操作,一键清空~ |
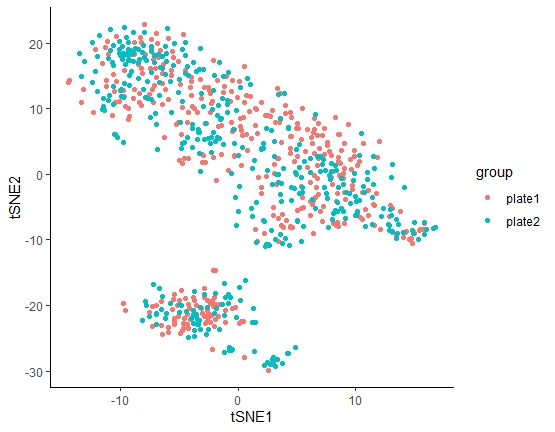
细胞亚群
1 | ######################### |
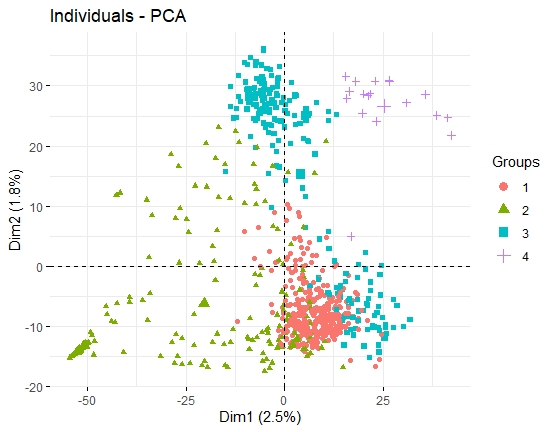

单细胞测序分析旨在分出不同细胞亚群(展现细胞间的异质性),力求寻找某类亚群与某特定生物学功能之间的联系。而要探讨细胞分群,就必须要知道PCA和tSNE。
PCA(Principal Component Analysis)
tSNE(t-Distributed Stochastic Neighbor Embedding)
什么样的算法才是最理想的能够将细胞分群的算法呢?
1)局部结构:属于同一个亚群的细胞,聚类尽可能近
2)全局结构:属于不同亚群的细胞,聚类尽可能分来
- PCA的方法侧重于去抓样本中隐含的主要效应,从而让差异大的样本在图上呈现较远的距离。常规RNA-seq项目中,处理效应、批次效应、离群效应等属于较大的效应,PCA的方法可以良好的去展示这些效应。
- 如果影响样本分组的不是主要效应,而是一些更小的效应,PCA则无法对样本进行准确的区分。scRNA-seq的可视化主要期望对各个细胞亚群有良好的区分。每次检测的上万甚至几十万个细胞中,几乎肯定可以区分出几十中细胞亚群,包括一些稀有的细胞。而区分这些细胞亚群(尤其是稀有细胞类型)的效应,往往不是主要效应(即大量基因的差异),而是一些微小效应(少量标记基因差异)。如果使用PCA进行分析的话,就会掩盖掉某些微小的但是有可能非常重要的细胞群。
- tSNE算法就属于可以同时兼顾局部结构和全局结构的非线性降维可视化算法。tSNE不同于PCA(PCA主要目标是尽量去抓取群体中的主要效益),tSNE算法的主要目标是:降维后的数据依然保持最为相似的紧密成簇。这就保证了哪怕某些稀有细胞只是少量基因区别于其他细胞亚群,在tSNE中依然可以与其他细胞有良好的区分。
结论:PCA是常规转录组常用的数据降维和样本关系可视化的方法,但针对群体单细胞转录组数据,tSNE是明显胜过PCA的方法!
scRNA-seq数据分析实战(一)