R语言apply、lapply、strsplit、%in%用法介绍
生信分析下游过程中,为了构建好可用于个性化分析的数据,往往要对原有数据进行整理,这个时候apply、lapply、strsplit、%in%就会在不同的地方发光✨发热🔥啦
R语言apply、lapply、strsplit、%in%用法介绍
apply函数
用于遍历数组中的行或列,并且使用指定函数来对其元素进行处理
1 | apply(x,MARGIN,FUN,...) |
x:数组、矩阵、数据框等
MARGIN:1表示行,2表示列
FUN:自定义的函数
1 | x<-matrix(rnorm(20),4,5) |
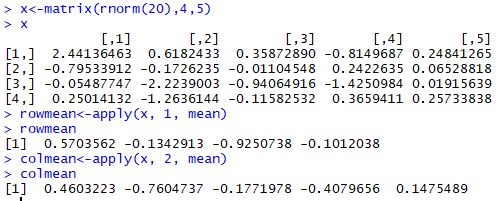
lapply函数
1 | lapply(x,FUN) |
lapply()函数中多出来的l代表的是list,所以lapply()和apply()的区别在于输出的格式,lapply()的输出是一个列表(list),所以lapply()函数不需要MARGIN参数
遍历列表向量内的每个元素,并且使用指定函数来对其元素进行处理。返回列表向量。
1 | y<-matrix(1:10,2,5) |
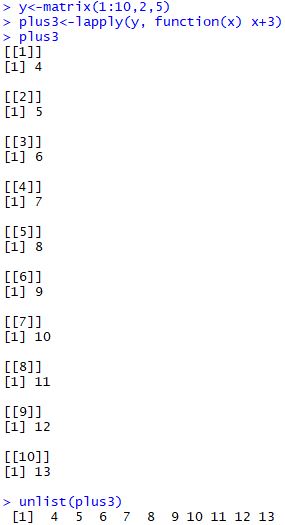
1 | y<-c("BABA","MAMA","YEYE","NAINAI") |

特定情况下,apply族函数比for、while函数更方便。
strsplit函数
1 | strsplit(x, split, fixed= F, perl= F, useBytes= F) |
参数x为字符串格式向量,函数依次对向量的每个元素进行拆分。
参数split为拆分位置的字串向量,即在哪个字串处开始拆分。
fixed= T则表示是用普通文本匹配或者正则表达式的精确匹配,用普通文本来匹配的运算速度要快些。
参数useBytes表示是否逐字节进行匹配,默认为FALSE,表示是按字符匹配而不是按字节进行匹配。
1 | s<-as.data.frame(c("444.dady_good-tempered.444","222.mom_bad-tempered.222","111.me_completely-lazy.111")) |

%in%函数
%in%函数在不同数据集间取相同的差异基因中非常有用!
1 | rm(list = ls()) |
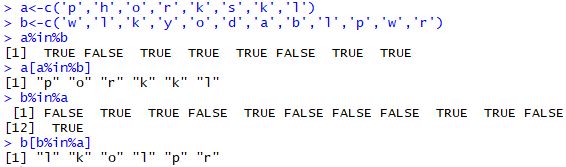
R语言apply、lapply、strsplit、%in%用法介绍